
Wir bringen den Bundestag ins 21. Jahrhundert!
Der Deutsche Bundestag ist das parlamentarische Herz unserer Demokratie. In unserem Grundgesetz ist festgeschrieben, dass der Bundestag öffentlich verhandeln soll.
Seit 1949 wird für jede Plenarsitzung ein stenografischer Bericht angefertigt, der jedes gesagte Wort der Sitzung dokumentiert. Diese Protokolle liegen als txt-, xml-, oder pdf-Dokumente auf den Servern des Bundestages und sind öffentlich abrufbar.
Die Protokolle und Transkripte der parlamentarischen Debatten sind eine reichhaltige Informationsquelle für Forschungsfragen. Die öffentlichen Dateiformate entsprechen jedoch leider noch nicht den Anforderungen für die Datenverarbeitung im digitalen Zeitalter.
Vor Open Discourse waren die Dokumente für die Öffentlichkeit nicht maschinenlesbar. Jede Recherche stellte einen langwierigen, händischen Prozess dar, der es nahezu unmöglich machte, alle Texte manuell zu lesen und zu analysieren.
Eine Lösung mit den technischen Mitteln des 21. Jahrhunderts ist schon lange erforderlich.
Warum hinkt der Deutsche Bundestag in Fragen der Digitalisierung so hinterher?
Die Geschichte und Herausforderungen
Angesichts der jüngsten Fortschritte auf dem Gebiet der Verarbeitung natürlicher Sprache und der Computerlinguistik, fällt rasch auf, dass es an Forschung zu parlamentarischen Debatten mangelt - vor allem in der deutschen Politikwissenschaft.
Einer der Hauptgründe ist laut dem Politikwissenschaftler Nicolas Bechter die Tatsache, dass sich die deutsche Forschung traditionell auf die politische Ideengeschichte ausrichtete und die theoretischen und methodischen Rahmenbedingungen lange fehlten, um Dokumente wie die Plenarprotokolle in die Forschung einzubeziehen.
Wir haben es uns zur Aufgabe gemacht, die im Grundgesetz definierte Öffentlichkeit des Bundestages durch moderne Wege der Datenverarbeitung wieder herzustellen, um jeder Bürgerin und jedem Bürger die Möglichkeit zu geben, den politischen Diskurs zu verfolgen und zu untersuchen.
Woher kommen die Daten?
Die Plenarprotokolle
Das Open Discourse Korpus basiert auf drei verschiedenen, unten aufgeführten Datenquellen, deren unterschiedliche Formate und Inhalte miteinander verknüpft wurden.
Das Open Discourse Korpus besteht aus den Plenarprotokollen, die für jede Parlamentssitzung des Deutschen Bundestages erstellt werden. Diese Berichte dokumentieren jede Rede im Parlament sowie jede Einmischung und andere Arten von Beiträgen (Lachen, Heiterkeit, Applaus usw.) der Politker:innen, die während der Reden stattfanden. Insgesamt besteht das Korpus aus über 200 Millionen Tokens aus fast 900.000 Reden in mehr als 4.000 verarbeiteten Protokollen. Das Open Discourse Korpus deckt insgesamt 99,7 Prozent aller Plenarprotokolle des Deutschen Bundestages ab.
Im Jahr 2013 hat der Deutsche Bundestag das E-Government-Gesetz (EGovG) verabschiedet. Erst mit diesem Gesetz verpflichtete sich die Regierung, Regierungsdokumente und Daten von öffentlichem Interesse in einem maschinenlesbaren Format bereitzustellen. Darüber hinaus definiert dieses Gesetz uneingeschränkte Nutzungs- und Verwertungsrechte für diese Daten (open Data).
Das Open Discourse-Korpus basiert auf drei verschiedenen, unten aufgeführten Datenquellen.
- Kerndatenquelle: Parlamentsprotokolle des Deutschen Bundestages
- Die Protokolle von der ersten bis zur 18. Wahlperiode werden als komprimiertes Archiv mit separaten XML-Dateien für jede Parlamentssitzung bereitgestellt. Die Protokolle der aktuellen 19. Periode werden als separate Dateien bereitgestellt.
- Metainformationen über die Mitglieder des Parlaments, die Vorsitzenden und die Mitglieder des Kabinetts
- Die Metainformationen stammen aus den Stammdaten aller MdBs (Stammdaten aller Abgeordneten seit 1949). Diese Daten werden vom Bundestag zur Verfügung gestellt und gepflegt.
- Es gibt seltene Fälle, in denen Politiker:innen Mitglied der Regierung (MG) sind und nie ein Mandat als Abgeordnete hatten. Diese Politiker:innen sind in den oben genannten Stammdaten nicht enthalten. Daher werden die Namen aller MG aus der deutschen Wikipedia übernommen und mit den Stammdaten zusammengeführt.
Das Vorgehen
Eine gründliche Datenaufbereitung ist das Fundament für die Qualität späterer Erkenntnisse.
In der Vorbereitung wurden alle Plenarprotokolle und die Stammdaten aller Abgeordneten abgerufen. Die Protokolle sind entweder nach Regex-Mustern oder nach XML-Tags (nur 19. Wahlperiode) in Inhaltsverzeichnis, gesprochenen Inhalt (die eigentliche Dokumentation der gehaltenen Reden) und Anhang unterteilt. Der gesprochene Inhalt jedes Dokuments wird extrahiert und vorübergehend gespeichert. Zusätzlich wird die Stammdaten-XML-Datei transformiert und in einen Datenrahmen reduziert und auch vorübergehend gespeichert.
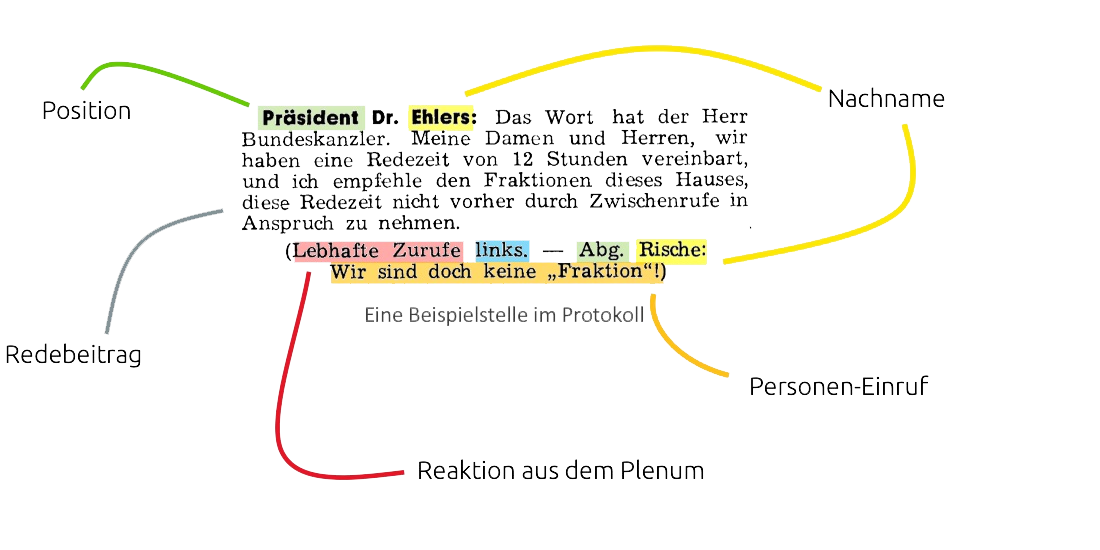
Im nächsten Schritt wurden eine die Fraktionstabelle, eine Politiker:innentabelle und eine Tabelle mit den gesprochenen Inhalten erstellt und extrahiert. Mit umfangreichen Regex-Muster können die Reden, die Person, die die Rede hält, die assoziierte Partei und Zwischenrufe durch das Plenum extrahieren werden. Ab der elften Wahlperiode werden Tagesordnungspunkte in den Protokollen verwendet, um den Rohtext aufzuteilen. Diese Unterteilung des Textes erhöht die Genauigkeit der angewendeten Regex-Muster. Der letzte Verarbeitungsschritt ist die Erstellung der Beitragstabelle.
Aufgrund dieser Datengrundlage können wir nun Algorithmen aus den Bereichen NLP (Natural Language Processing), Machine Learning, Deep Learning etc. auf die Daten anwenden, um Fragen zu beantworten, die bisher nicht (ohne großen Aufwand) beantwortbar waren.

Der datenbasierte Ansatz unseres Verfahrens sichert die Reproduzierbarkeit und Validierbarkeit/Falsifizierbarkeit aller Analysen und erfüllt somit den Anspruch der Wissenschaftlichkeit.
Die Verarbeitung der oben genannten Datenquellen und die Erstellung der Datenbank ist ein vollautomatischer und reproduzierbarer Vorgang. Auf diese Weise können wir sicherstellen, dass die Erstellung des Open Discourse Korpus maximal transparent und unabhängig ist. Die Codebasis kann aus dem zugehörigen GitHub-Repository abgerufen werden.
Welches Potenzial steckt in den Daten?
Mögliche Analysen und Tools
Die aufwendige Datenaufbereitung erlaubt komplexe Analysen und vielschichtige, mehrdimensionale Untersuchungen.
Unsere bisherige Arbeit hat sich vorrangig auf die Aufarbeitung und Bereitstellung der Daten konzentriert. Die vielfältigen Analysemöglichkeiten liegen noch offen vor uns und vor Ihnen. Jetzt sind Sie gefragt, Ihre eigenen Fragestellungen mit den Daten zu beantworten und eigene Recherchen durchzuführen!
Wir stellen unsere aufbereitete Datenbank an dieser Stelle zur Verfügung und geben die Nutzung, Weiterverwendung und Weiterentwicklung frei. Bitte verweisen Sie auf unser Projekt und diese Website in Ihren Quellenangaben.
Das Data Paper
Es erfordert Mühe, Daten vorzubereiten, zu kuratieren und zu beschreiben. Genauso braucht es Zeit, das Data Paper zu schreiben. Aktuell arbeiten wir noch an dem Dokument und bitten Sie um noch ein wenig Geduld. Tragen Sie sich gern in unseren Newsletter ein, wenn Sie über die Veröffentlichung informiert werden wollen.

Datenzugriff über das Harvard Dataverse
Sie möchten den Datensatz für eine eigene Analyse nutzen oder ihn einfach eigenständig durchstöbern?
Wir stellen unsere aufbereitete Datenbank* open source zur Verfügung. Wir würden uns freuen, wenn Sie uns bei Nutzung des Datensatzes zitieren:
Richter, F.; Koch, P.; Franke, O.; Kraus, J.; Kuruc, F.; Thiem, A.; Högerl, J.; Heine, S.; Schöps, K., 2020, "Open Discourse", https://doi.org/10.7910/DVN/FIKIBO, Harvard Dataverse
Wir arbeiten gerade an einer detaillierten, wissenschaftlichen Dokumentation über die Open Discourse Daten. Wir werden dieses Data Paper in Q1 2021 veröffentlichen - die entsprechenden Informationen finden Sie dann ebenfalls hier.
* Die Datenbank befindet sich momentan in Version 1 und soll zukünftig weiter verbessert und um neue Plenarprotokolle erweitert werden.GitHub Repository
Unseren Source Code und Docker Container finden Sie in unserem Github Repository
Für vollständige Reproduzierbarkeit und Offenheit, stellen wir den Source Code, mit dem die Open-Discourse Daten erstellt wurden, auf GitHub zur Verfügung.
Auch stellen wir hier ein Docker Image der Datenbank zur Verfügung.
Diese können Sie benutzen, um die Datenbank ganz einfach lokal aufzusetzen.
Ebenso können Sie so die Limitierungen, der obigen Volltextsuche (max. 50 Suchergebnisse) entfernen und erhalten ein noch umfangreicheres Werkzeug für Ihre Recherchen.
Wir bieten Ihnen auch die Möglichkeit sich am Projekt durch Pull Requests zu beteiligen oder das Repository zu Forken und an Ihre Anforderungen anzupassen.