
Open Discourse - Analyse der Plenarprotokolle des Deutschen Bundestages seit 1949
Wie Data Science den Weg zu politischem Diskurs demokratisiert
Open Discourse hat die Plenarprotokolle des deutschen Bundestages seit 1949 aufgebrochen und analysierbar gemacht - und zwar für Mensch und Maschine. Die Plattform ermöglicht erstmals den Zugang und die Recherche in den über 800.000 Redebeiträgen der letzten 70 Jahre.

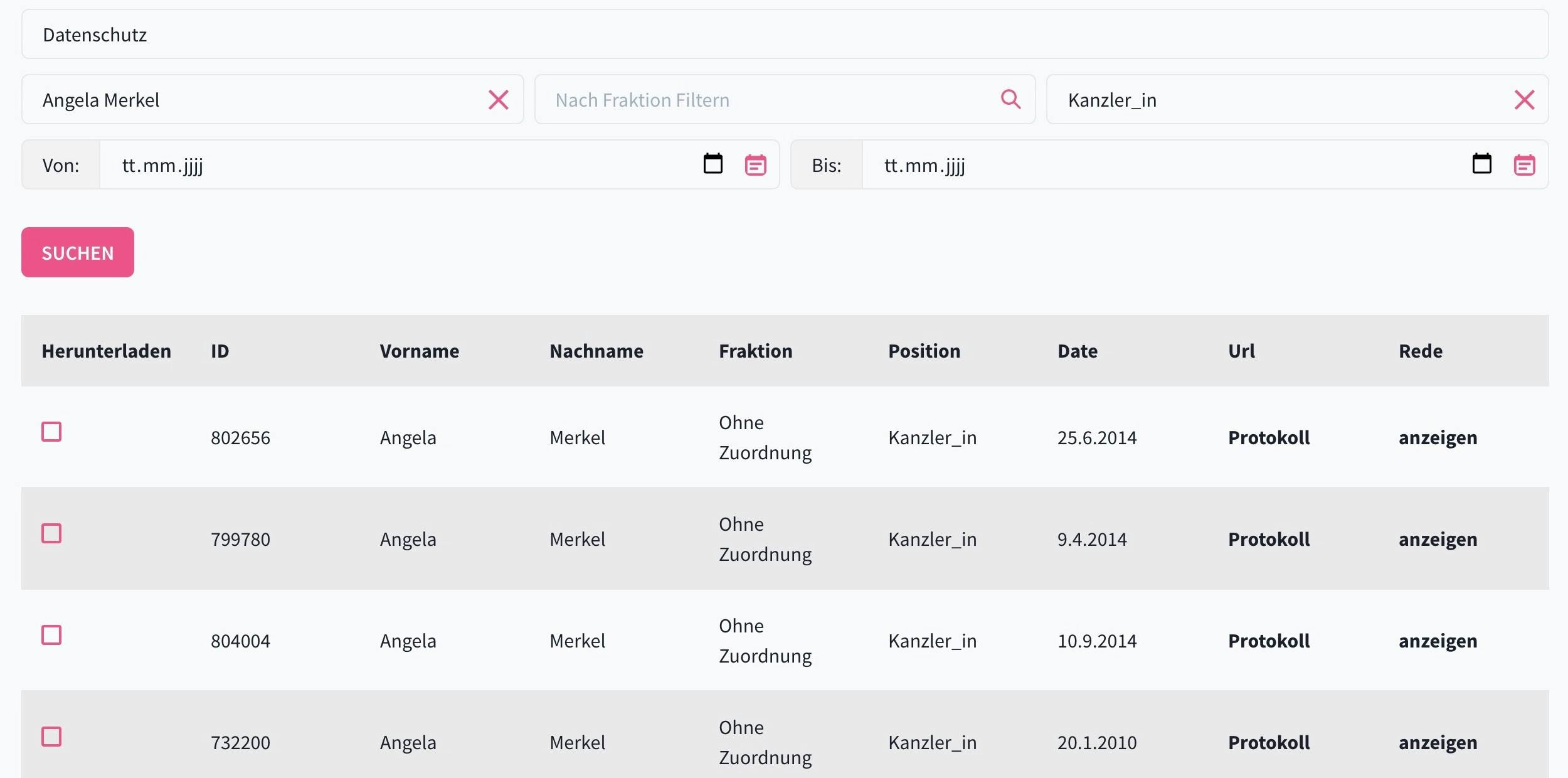
Die Datenbank hinter Open Discourse ist die erste granulare, umfassende und maschinenlesbare Aufbereitung jedes jemals gesprochenen Wortes in den Parlamentssitzungen des deutschen Bundestages. Sie ermöglicht erstmalig gefilterte Recherchen in den Reden und Zwischenrufen der Politker:innen und Fraktionen.
Für einen offenen Diskurs und eine wissenschaftliche Auseinandersetzung mit politischer Sprache.
Seiten Text
Redebeiträge
Reaktionen & Zwischenrufe
Open Dicsourse bei der re:publica
Was ist Open Discourse genau? Anja und Jakob haben bei der Re:publica 2021 unser Projekt vorgestellt.
An der Schnittstelle zwischen Politikwissenschaft und Data Science
Open Discourse erleichtert den Zugang zu über 800.000 Reden seit 1949 und ermöglicht eine strukturierte Stichwortrecherche auf der Grundlage von Politiker:innen, Koalitionen und Positionen.
Mit Methoden der Informatik und Computerlinguistik haben wir alle Reden, Zwischenrufe, Anfragen uvm. den jeweiligen Politiker:innen und Fraktionen zugeordnet und durchsuchbar gemacht, sowie zahlreiche Metainformationen hinzugefügt.
- Wie hat sich der politische Diskurs in den letzten 70 Jahren verändert?
- Wie ist die thematische Nähe von Politiker:innen zueinander?
- Wie hoch ist der relative Anteil von Frauen und Männern, die als Abgeordnete der verschiedenen Parteien sprechen?
Bürger:innen, Journalist:innen und Wissenschaftler:innen können jetzt den gesamten Datensatz für ihre eigene Forschung herunterladen und auf Muster untersuchen.
Open Discourse ermöglicht einzigartige Einblicke in die Herzkammer der deutschen Politik und holt so den politischen Diskurs ins 21. Jahrhundert.
Welches Potenzial steckt in den Daten?
Auswertungen und Ergebnisse
Die Datenbank ermöglicht komplexe Analysen der politischen Sprache und erlaubt es, die Reden auf Muster zu untersuchen.
Hier werden Ihnen bald noch mehr Analysen von uns und von anderen Personen zeigen können - wir bitten um noch etwas Geduld.
Die Zusammenarbeit mit anderen Partner:innen kann dazu beitragen, deutsche Parlamente dauerhaft zu öffnen und politischen Diskurs zu demokratisieren.
Die Open Discourse Daten für Forschung, Journalismus und Civil Science
Verwendung und Präsenz von Open Discourse
Der Open Discourse Datensatz wurde bereits von verschiedenen Akteur:innen für Forschungsprojekte und datengetriebene Berichterstattungen genutzt.
Wählen Sie hier aus, in welches Projekt Sie gern einmal reinschauen möchten:





CorrelAid
Datenbasiertes Storytelling
CorrelAid ist ein gemeinnütziges Netzwerk von Data Scientists, die die Welt durch Data Science zum Positiven verändern wollen. Ziel der Zusammenarbeit mit unserem Projekt ist es, NLP-Techniken auf den Datensatz anzuwenden und Einblicke zu gewinnen, worüber die deutschen Abgeordneten seit der Gründung des Bundestages gesprochen haben.
Über Natural language Processing zu geschichtlichen Erkenntnissen
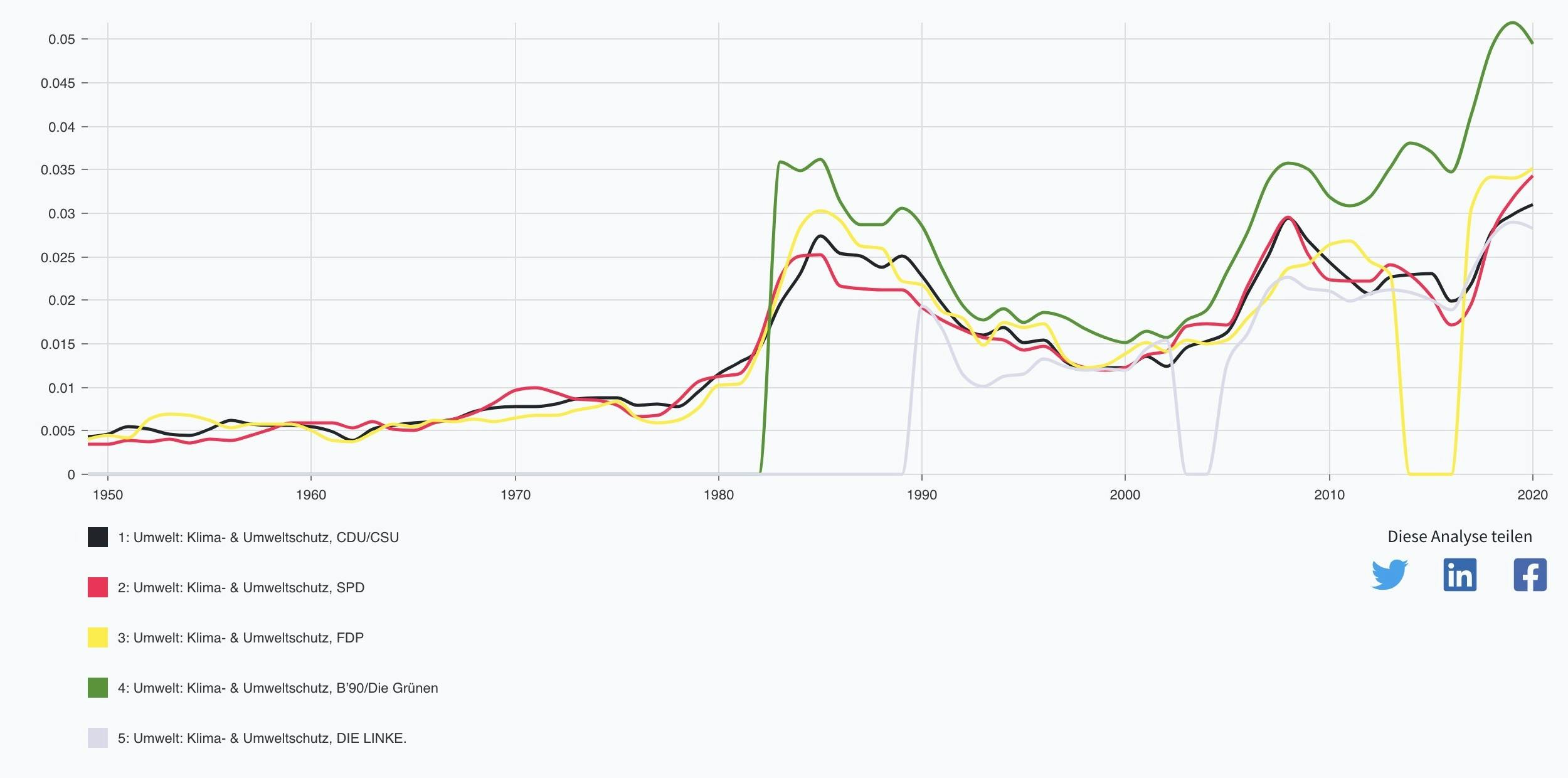
Im Sommer 2020 haben sich 8 ehrenamtliche Data Scientists mit dem Datensatz auseinandergesetzt. Untersucht wurde inwiefern sich Debatten im Bundestag verändert haben und ob Diskursverschiebungungen in geschichtlichen Zusammenhängen stehen.
In der Arbeit mit dem Datensatz hat sich das Team folgende Ziele gesetzt:
- mehr über angewandtes NLP erfahren
- kreative Wege finden, um die Daten zu analysieren und zu visualisieren
Das genaue Ziel, d. H. der Fokus der Analyse, wurde innerhalb der beiden Untergruppen entwickelt. Das Ergebnis sollte sich primär nicht auf ein politikwissenschaftlichen Ansatz konzentrieren, sondern interessante oder unterhaltsame Muster in der Historie finden, die eine Geschichte erzählen wie sich Politik und Gesellschaft im Laufe der Jahre verändert haben.
Auf der CorrelCon-Tagung im November wurde bereits ein Ergebnis vorgestellt:


Für einen offenen Diskurs mit den technologischen Mitteln des 21. Jahrhunderts.
Warum ist das wichtig?
Zugang und Durchsuchbarkeit der Dokumente
Die im Grundgesetz definierte Öffentlichkeit des Bundestages muss durch moderne Wege der Datenverarbeitung ausgebaut werden.
In seiner über 70 jährigen Geschichte war der Bundestag immer eins: Ein Ort der lebhaften Debatte und parlamentarischer Marktplatz unserer Demokratie. Egal ob Grundsätzliches oder Tagesaktuelles, ziemlich jedes Thema wurde besprochen, kritisiert oder beklatscht. Praktisch alle Dinge in der täglichen Lebenswelt haben eine politische Dimension, insbesondere eine bundespolitische. Im Grundgesetz ist definiert, dass die Abgeordneten die Vertreter:innen des gesamten Volkes sind und dass der Bundestag öffentlich verhandelt. Wir alle haben somit das Recht, die Inhalte und Vorgänge im Parlament transparent mitverfolgen zu dürfen.
Bisher lagen die Protokolle zwar auf den Serven des Bundestages, aber die Einsicht in die Dokumenten ist umständlich und das Format der Dokumente für eine moderne Datenverarbeitung nicht geeignet. Auf Open Discourse können Bürger:innen, Journalist:innen und Wissenschaftler:innen jetzt leicht zugänglich und kostenfrei über die Volltextsuche der Plattform die Plenarprotokolle nach Stichworten, Politiker:innen und Ämtern durchsuchen und die Ergebnisse für Ihre Arbeit, Forschung und natürlich für das eigene Interesse nutzen.
Wie funktioniert das?
Die Herangehensweise
Data Science trifft auf Plenarprotokolle

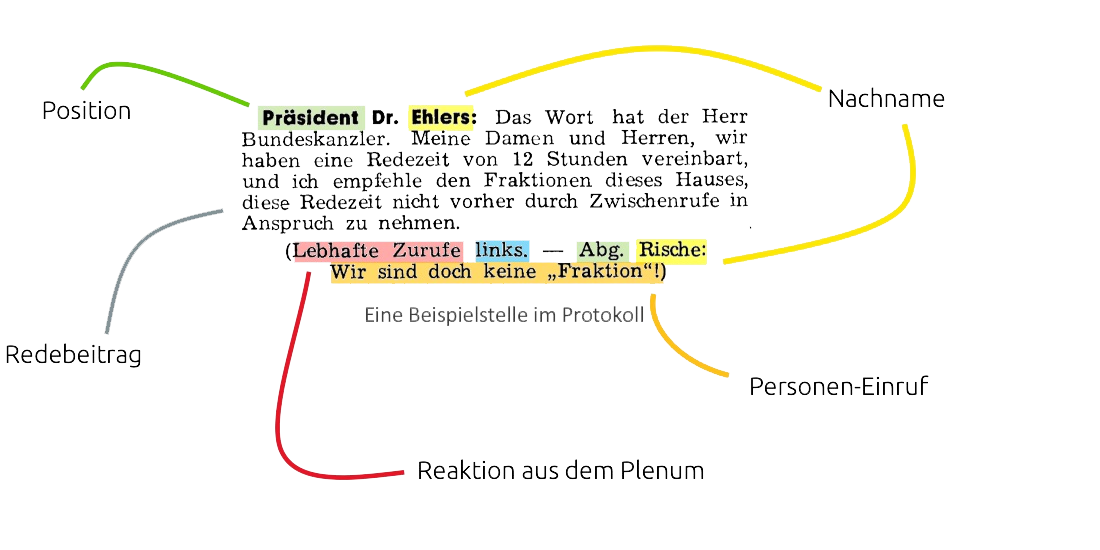
Wir haben mit verschiedenen Methoden der Informatik und Computerlinguistik die Plenarprotokolle aufgebrochen und alle Redebeiträge, Zwischenrufe, Rückfragen etc. der jeweiligen Politiker:innen und Fraktionen zugeordnet und durchsuchbar gemacht.
Open Discourse verfügt damit über eine Datenbank, die jedes bisher in Plenarsitzungen gesprochene Wort strukturiert abbildet und sowohl für Menschen als auch Maschinen lesbar zur Verfügung stellt. Diese aufbereiteten Daten bilden die Grundlage, um Algorithmen aus den Bereichen NLP (Natural Language Processing), Machine Learning, Deep Learning etc. auf die Daten anzuwenden und umfangreiche Analysen durchzuführen.
Der programmatische Ansatz unseres Verfahrens sichert die Reproduzierbarkeit und Validierbarkeit/Falsifizierbarkeit aller Analysen und erfüllt somit den Anspruch der Wissenschaftlichkeit.
Wer steckt dahinter?
Unser Beitrag zur Demokratie
Open Discourse ist ein gemeinnütziges Forschungsprojekt.
Das Open Discourse Korpus ist selbstfinanziert, unabhängig und aus den Fähigkeiten und Motivationen der Mitarbeiter:innen der Limebit GmbH gewachsen. Die Plattform ist unser Beitrag zur Demokratisierung des Zugangs zu politischen Themen und eine Herzensangelegenheit.
Möchten Sie uns Feedback geben oder haben Sie Interesse Ihre Fähigkeiten, Ideen oder Anmerkungen in irgendeiner Form zur Verfügung zu stellen? Kontaktieren Sie uns gern!